Tutorials
Discrete Markov chains
Initializing a Markov chain using some data.
>>> import mchmm as mc
>>> a = mc.MarkovChain().from_data('AABCABCBAAAACBCBACBABCABCBACBACBABABCBACBBCBBCBCBCBACBABABCBCBAAACABABCBBCBCBCBCBCBAABCBBCBCBCCCBABCBCBBABCBABCABCCABABCBABC')
Now, we can look at the observed transition frequency matrix:
>>> a.observed_matrix
array([[ 7., 18., 7.],
[19., 5., 29.],
[ 5., 30., 3.]])
And the observed transition probability matrix:
>>> a.observed_p_matrix
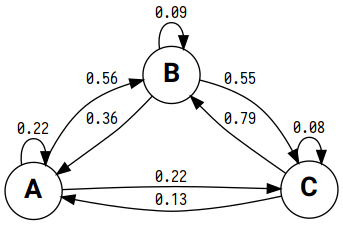
array([[0.21875 , 0.5625 , 0.21875 ],
[0.35849057, 0.09433962, 0.54716981],
[0.13157895, 0.78947368, 0.07894737]])
You can visualize your Markov chain. First, build a directed graph with graph_make() method of MarkovChain object.
Then render() it.
>>> graph = a.graph_make(
format="png",
graph_attr=[("rankdir", "LR")],
node_attr=[("fontname", "Roboto bold"), ("fontsize", "20")],
edge_attr=[("fontname", "Iosevka"), ("fontsize", "12")]
)
>>> graph.render()
Here is the result:
Pandas can help us annotate columns and rows:
>>> import pandas as pd
>>> pd.DataFrame(a.observed_matrix, index=a.states, columns=a.states, dtype=int)
A B C
A 7 18 7
B 19 5 29
C 5 30 3
Viewing the expected transition frequency matrix:
>>> a.expected_matrix
array([[ 8.06504065, 13.78861789, 10.14634146],
[13.35772358, 22.83739837, 16.80487805],
[ 9.57723577, 16.37398374, 12.04878049]])
Calculating Nth order transition probability matrix:
>>> a.n_order_matrix(a.observed_p_matrix, order=2)
array([[0.2782854 , 0.34881028, 0.37290432],
[0.1842357 , 0.64252707, 0.17323722],
[0.32218957, 0.21081868, 0.46699175]])
Carrying out a chi-squared test:
>>> a.chisquare(a.observed_matrix, a.expected_matrix, axis=None)
Power_divergenceResult(statistic=47.89038802624337, pvalue=1.0367838347591701e-07)
Finally, let’s simulate a Markov chain given our data.
>>> ids, states = a.simulate(10, start='A', seed=np.random.randint(0, 10, 10))
>>> ids
array([0, 2, 1, 0, 2, 1, 0, 2, 1, 0])
>>> states
array(['A', 'C', 'B', 'A', 'C', 'B', 'A', 'C', 'B', 'A'], dtype='<U1')
>>> "".join(states)
'ACBACBACBA'